Chúng ta sẽ thực hiện bài toán phân loại đối tượng ( object classification) sử dụng Keras với Tensorflow
Bước 1 : Chuẩn bị tạo cây thư mục và các file có tên như sau:
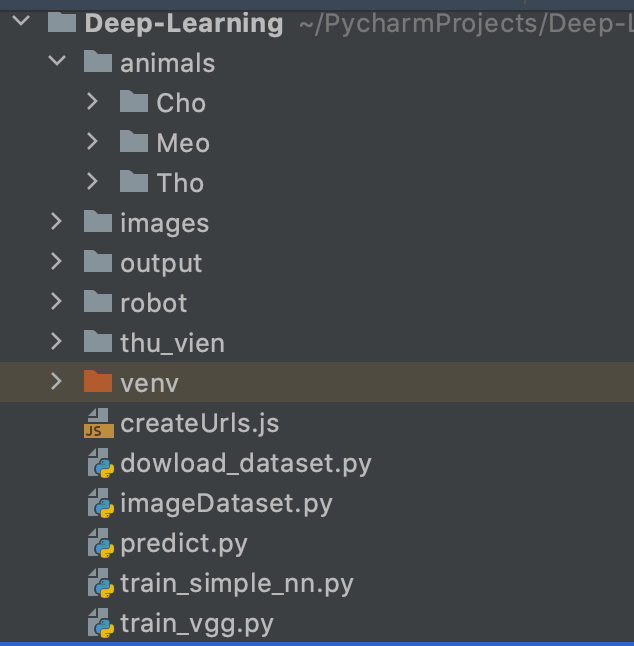
Trong đó thư mục animals chứa tập ảnh dataset về chó, mèo và thỏ
Bước 2: Tải bộ dữ liệu của bạn từ ổ đĩa vào chương trình
Tạo file train_simple_nn.py và thêm đoạn code sau:
Thêm các thư viện:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
<span style="color: #993300;"><strong># đặt mathplotlib làm backen (phụ trợ) để có thể lưu các số liệu ở background background( chạy ngầm)</strong></span> <span style="color: #993300;"><strong>import matplotlib</strong></span> <span style="color: #993300;"><strong>matplotlib.use("Agg")</strong></span> <span style="color: #993300;"><strong># thêm các thư viện cần thiết</strong></span> <span style="color: #993300;"><strong>#hư viện scikit-learning sẽ giúp chúng tôi mã hóa các nhãn,</strong></span> <span style="color: #993300;"><strong># tách dữ liệu để đào tạo / kiểm tra và tạo báo cáo đào tạo trong thiết bị đầu cuối</strong></span> <span style="color: #993300;"><strong>from sklearn.preprocessing import LabelBinarizer</strong></span> <span style="color: #993300;"><strong>from sklearn.model_selection import train_test_split</strong></span> <span style="color: #993300;"><strong>from sklearn.metrics import classification_report</strong></span> <span style="color: #993300;"><strong>#keras giao diện người dùng cấp cao và phụ trợ trong TensorFlow</strong></span> <span style="color: #993300;"><strong>from tensorflow.keras.models import Sequential</strong></span> <span style="color: #993300;"><strong>from tensorflow.keras.layers import Dense</strong></span> <span style="color: #993300;"><strong>from tensorflow.keras.optimizers import SGD</strong></span> <span style="color: #993300;"><strong>#sử dụng mô-đun để tạo danh sách các đường dẫn tệp hình ảnh để đào tạo</strong></span> <span style="color: #993300;"><strong>from imutils import paths</strong></span> <span style="color: #993300;"><strong>import matplotlib.pyplot as plt</strong></span> <span style="color: #993300;"><strong>#NumPy dành cho xử lý số với Python</strong></span> <span style="color: #993300;"><strong>import numpy as np</strong></span> <span style="color: #993300;"><strong>import argparse</strong></span> <span style="color: #993300;"><strong>import random</strong></span> <span style="color: #993300;"><strong>import pickle</strong></span> <span style="color: #993300;"><strong>import cv2</strong></span> <span style="color: #993300;"><strong>import os</strong></span> |
Tiếp theo xây dựng trình phân tích cú pháp và đọc đối số nhập vào
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
<span style="color: #993300;"><strong># xây dựng trình phân tích cú pháp và đọc đối số nhập vào</strong></span> <span style="color: #993300;"><strong>ap = argparse.ArgumentParser()</strong></span> <span style="color: #993300;"><strong>#Đường dẫn đến tập dữ liệu về hình ảnh trên ổ đĩa</strong></span> <span style="color: #993300;"><strong>ap.add_argument("-d", "--dataset", required=True,</strong></span> <span style="color: #993300;"><strong> help="path to input dataset of images")</strong></span> <span style="color: #993300;"><strong>#Mô hình được tuần tự hóa và xuất ra ổ cứng. Model sẽ được lưu ở thư mục output.</strong></span> <span style="color: #993300;"><strong>ap.add_argument("-m", "--model", required=True,</strong></span> <span style="color: #993300;"><strong> help="path to output trained model")</strong></span> <span style="color: #993300;"><strong>#Các nhãn tập dữ liệu được tuần tự hóa vào ổ cứng.</strong></span> <span style="color: #993300;"><strong>#label sẽ được lưu ở thư mục output.</strong></span> <span style="color: #993300;"><strong>ap.add_argument("-l", "--label-bin", required=True,</strong></span> <span style="color: #993300;"><strong> help="path to output label binarizer")</strong></span> <span style="color: #993300;"><strong>#hình ảnh biểu đồ đầu ra đào tạo .</strong></span> <span style="color: #993300;"><strong># biểu đồ này kiểm tra xem có thừa / thiếu dữ liệu hay không.</strong></span> <span style="color: #993300;"><strong>ap.add_argument("-p", "--plot", required=True,</strong></span> <span style="color: #993300;"><strong> help="path to output accuracy/loss plot")</strong></span> <span style="color: #993300;"><strong>args = vars(ap.parse_args())</strong></span> |
Tải dữ liệu ảnh từ ổ đĩa
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
<span style="color: #993300;"><strong># khởi tạo data và nhãn</strong></span> <span style="color: #993300;"><strong>print("[INFO] loading images...")</strong></span> <span style="color: #993300;"><strong>#Khởi tạo danh sách. Các mảng này sau này sẽ trở thành mảng NumPy.</strong></span> <span style="color: #993300;"><strong>data = []</strong></span> <span style="color: #993300;"><strong>labels = []</strong></span> <span style="color: #993300;"><strong>#lấy các đường dẫn hình ảnh và ngẫu nhiên trộn chúng với nhau</strong></span> <span style="color: #993300;"><strong>#Lấy và trộn ngẫu nhiên ,thuận tiện sẽ tìm thấy tất cả các đường dẫn</strong></span> <span style="color: #993300;"><strong># cho tất cả các hình ảnh đầu vào trong thư mục trước khi sắp xếp.</strong></span> <span style="color: #993300;"><strong>imagePaths = sorted(list(paths.list_images(args["dataset"])))</strong></span> <span style="color: #993300;"><strong>random.seed(42)</strong></span> <span style="color: #993300;"><strong>random.shuffle(imagePaths)</strong></span> <span style="color: #993300;"><strong># vòng lặp cho ảnh đầu vào</strong></span> <span style="color: #993300;"><strong>for imagePath in imagePaths:</strong></span> <span style="color: #993300;"><strong> # tải ảnh, thay đổi kích thứơc về 32x32 pixels</strong></span> <span style="color: #993300;"><strong> # (bỏ qua tỷ lệ khung hình), làm phẳng hình ảnh thành hình ảnh 32x32x3 = 3072 pixel</strong></span> <span style="color: #993300;"><strong> # tạo một danh sách và lưu trữ hình ảnh trong danh sách đó</strong></span> <span style="color: #993300;"><strong> image = cv2.imread(imagePath)</strong></span> <span style="color: #993300;"><strong> #Thay đổi kích thước thành pixel (bỏ qua tỷ lệ khung hình)</strong></span> <span style="color: #993300;"><strong> # Nó rất quan trọng đối với hình ảnh một cách chính xác bởi vì mạng nơ-ron này</strong></span> <span style="color: #993300;"><strong> # yêu cầu những kích thước này.</strong></span> <span style="color: #993300;"><strong> # Mỗi mạng nơ-ron sẽ yêu cầu các kích thước khác nhau,</strong></span> <span style="color: #993300;"><strong> # vì vậy chỉ cần lưu ý điều này.</strong></span> <span style="color: #993300;"><strong> # Việc làm phẳng dữ liệu cho phép truyền cường độ pixel thô</strong></span> <span style="color: #993300;"><strong> # đến các nơ-ron của lớp đầu vào một cách dễ dàng. </strong></span> <span style="color: #993300;"><strong> image = cv2.resize(image, (32, 32)).flatten()</strong></span> <span style="color: #993300;"><strong> data.append(image)</strong></span> <span style="color: #993300;"><strong> # trích xuất nhãn lớp từ đường dẫn hình ảnh và cập nhật</strong></span> <span style="color: #993300;"><strong> # danh sách nhãn</strong></span> <span style="color: #993300;"><strong> label = imagePath.split(os.path.sep)[-2]</strong></span> <span style="color: #993300;"><strong> labels.append(label)</strong></span> <span style="color: #993300;"><strong># chia tỷ lệ cường độ pixel thô thành phạm vi [0, 1]</strong></span> <span style="color: #993300;"><strong>data = np.array(data, dtype="float") / 255.0</strong></span> <span style="color: #993300;"><strong>labels = np.array(labels)</strong></span> |
Bước 3 : Xây dựng training và test
hoàn thành theo code sau:
|
1 2 3 4 5 6 7 8 9 10 |
<span style="color: #993300;"><strong># phân vùng dữ liệu thành các phần đào tạo và thử nghiệm bằng cách</strong></span> <span style="color: #993300;"><strong># sử dụng 75% dữ liệu để đào tạo và 25% còn lại để thử nghiệm</strong></span> <span style="color: #993300;"><strong>(trainX, testX, trainY, testY) = train_test_split(data,</strong></span> <span style="color: #993300;"><strong> labels, test_size=0.25, random_state=42)</strong></span> <span style="color: #993300;"><strong># chuyển đổi nhãn từ số nguyên sang vectơ (dành cho 2 lớp, nhị phân</strong></span> <span style="color: #993300;"><strong># phân loại bạn nên sử dụng hàm Keras 'to_categorical</strong></span> <span style="color: #993300;"><strong># thay vào đó là LabelBinarizer của scikit-learning sẽ không trả về vector)</strong></span> <span style="color: #993300;"><strong>lb = LabelBinarizer()</strong></span> <span style="color: #993300;"><strong>trainY = lb.fit_transform(trainY)</strong></span> <span style="color: #993300;"><strong>testY = lb.transform(testY)</strong></span> |
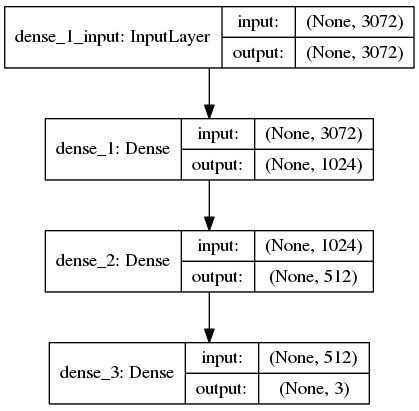
Bước 4: Xác định kiến trúc mô hình Keras. Bước tiếp theo là xác định kiến trúc mạng nơ-ron của chúng ta bằng Keras. Ở đây chúng ta sẽ sử dụng một mạng với một lớp đầu vào, hai lớp ẩn và một lớp đầu ra
|
1 2 3 4 5 |
<strong><span style="color: #993300;"># xác định kiến trúc 3072-1024-512-3 bằng Keras</span></strong> <strong><span style="color: #993300;">model = Sequential()</span></strong> <strong><span style="color: #993300;">model.add(Dense(1024, input_shape=(3072,), activation="sigmoid"))</span></strong> <strong><span style="color: #993300;">model.add(Dense(512, activation="sigmoid"))</span></strong> <strong><span style="color: #993300;">model.add(Dense(len(lb.classes_), activation="softmax"))</span></strong> |
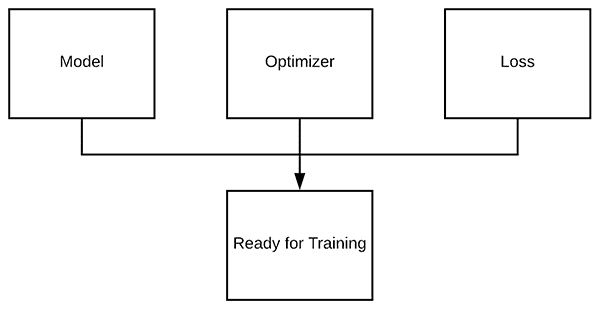
Bước 5: Biên dịch mô hình keras
|
1 2 3 4 5 6 7 8 9 |
<span style="color: #993300;"><strong># khởi tạo tốc độ học ban đầu và epochs để đào tạo</strong></span> <span style="color: #993300;"><strong>INIT_LR = 0.01</strong></span> <span style="color: #993300;"><strong>EPOCHS = 80</strong></span> <span style="color: #993300;"><strong># biên dịch mô hình bằng cách sử dụng SGD làm trình tối ưu hóa và phân loại</strong></span> <span style="color: #993300;"><strong># tổn thất chéo entropy (bạn sẽ muốn sử dụng binary_crossentropy để phân loại 2 lớp)</strong></span> <span style="color: #993300;"><strong>print("[INFO] training network...")</strong></span> <span style="color: #993300;"><strong>opt = SGD(lr=INIT_LR)</strong></span> <span style="color: #993300;"><strong>model.compile(loss="categorical_crossentropy", optimizer=opt,</strong></span> <span style="color: #993300;"><strong> metrics=["accuracy"])</strong></span> |
bước 6: Điều chỉnh mô hình với dữ liệu

|
1 2 3 |
<strong><span style="color: #993300;"># đào tạo mạng nơ-ron</span></strong> <strong><span style="color: #993300;">H = model.fit(x=trainX, y=trainY, validation_data=(testX, testY),</span></strong> <strong><span style="color: #993300;"> epochs=EPOCHS, batch_size=32)</span></strong> |
Bước 7:Đánh giá mô hình keras

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
<span style="color: #993300;"><strong># đánh giá mạng</strong></span> <span style="color: #993300;"><strong>print("[INFO] evaluating network...")</strong></span> <span style="color: #993300;"><strong>predictions = model.predict(x=testX, batch_size=32)</strong></span> <span style="color: #993300;"><strong>print(classification_report(testY.argmax(axis=1),</strong></span> <span style="color: #993300;"><strong> predictions.argmax(axis=1), target_names=lb.classes_))</strong></span> <span style="color: #993300;"><strong># vẽ biểu đồ về độ chính xác và mất mát trong quá trình đào tạo</strong></span> <span style="color: #993300;"><strong>N = np.arange(0, EPOCHS)</strong></span> <span style="color: #993300;"><strong>plt.style.use("ggplot")</strong></span> <span style="color: #993300;"><strong>plt.figure()</strong></span> <span style="color: #993300;"><strong>plt.plot(N, H.history["loss"], label="train_loss")</strong></span> <span style="color: #993300;"><strong>plt.plot(N, H.history["val_loss"], label="val_loss")</strong></span> <span style="color: #993300;"><strong>plt.plot(N, H.history["accuracy"], label="train_acc")</strong></span> <span style="color: #993300;"><strong>plt.plot(N, H.history["val_accuracy"], label="val_acc")</strong></span> <span style="color: #993300;"><strong>plt.title("Training Loss and Accuracy (Simple NN)")</strong></span> <span style="color: #993300;"><strong>plt.xlabel("Epoch #")</strong></span> <span style="color: #993300;"><strong>plt.ylabel("Loss/Accuracy")</strong></span> <span style="color: #993300;"><strong>plt.legend()</strong></span> <span style="color: #993300;"><strong>plt.savefig(args["plot"])</strong></span> |
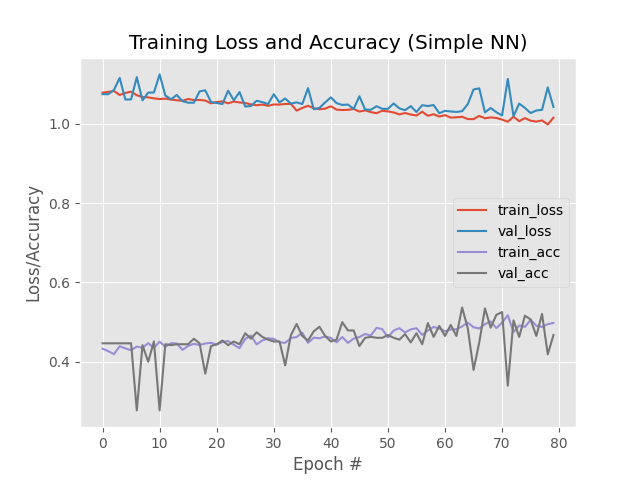
cuối cùng lưu mô hình đạo tạo lại:
|
1 2 3 4 5 6 |
<strong><span style="color: #993300;"># lưu mô hình và nhãn binarizer vào đĩa</span></strong> <strong><span style="color: #993300;">print("[INFO] serializing network and label binarizer...")</span></strong> <strong><span style="color: #993300;">model.save(args["model"], save_format="h5")</span></strong> <strong><span style="color: #993300;">f = open(args["label_bin"], "wb")</span></strong> <strong><span style="color: #993300;">f.write(pickle.dumps(lb))</span></strong> <strong><span style="color: #993300;">f.close()</span></strong> |
bạn mở terminal của pycharm gõ câu lệnh sau để chạy chương trình training như sau
|
1 |
<span style="color: #993300;"><strong>python train_simple_nn.py --dataset animals --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png</strong></span> |

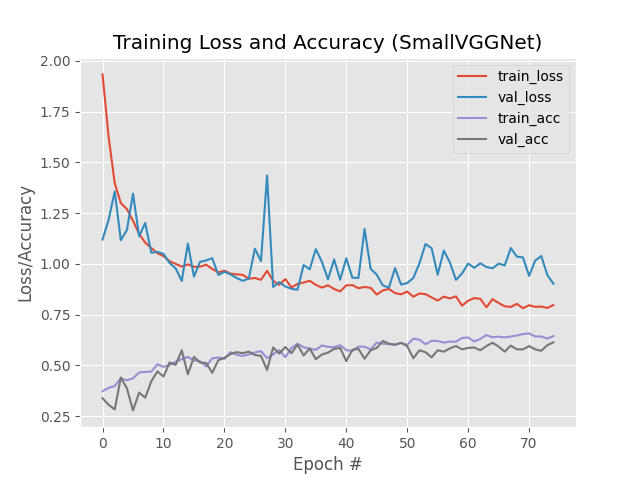
kết quả hiển thị như sau:
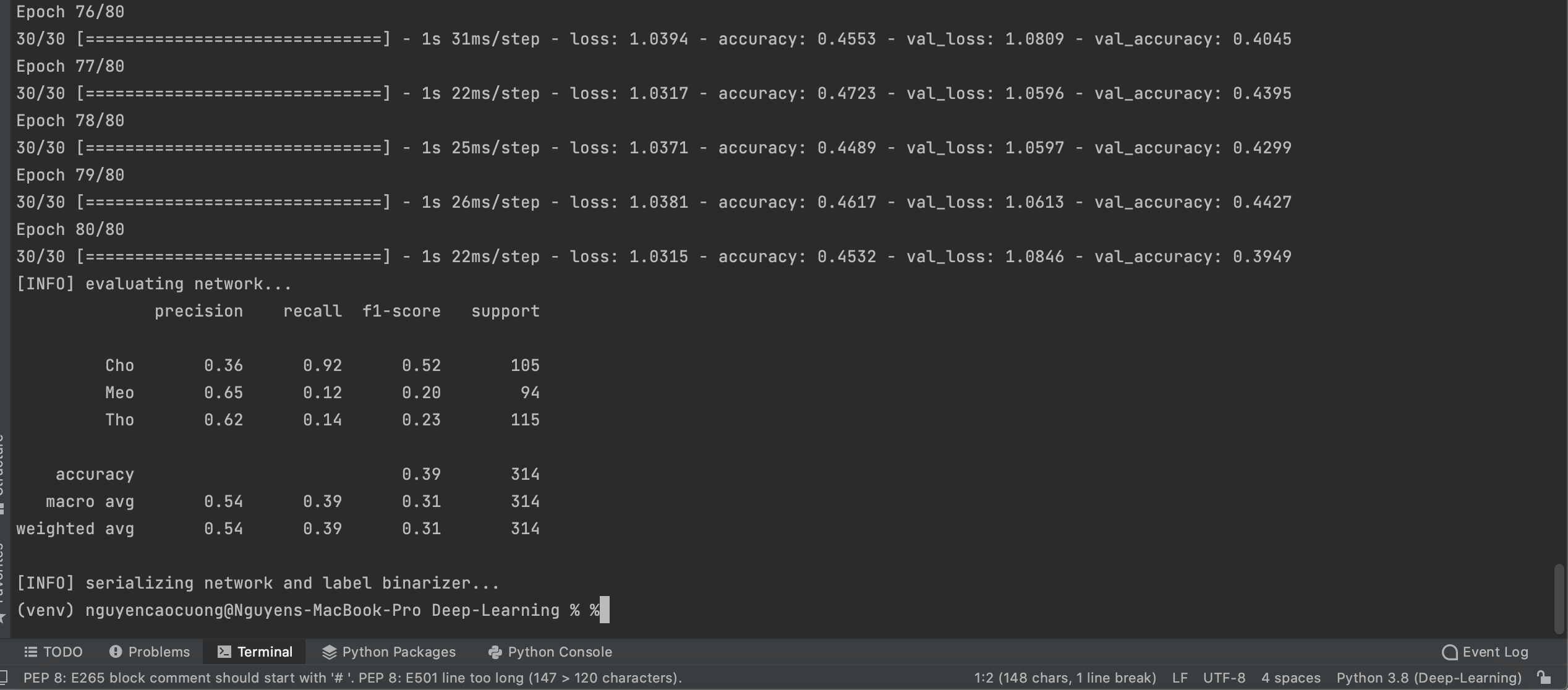
Mạng này nhỏ và khi được kết hợp với một tập dữ liệu nhỏ, chỉ mất gần 2 giây mỗi epoch trên CPU.
Ở đây, bạn có thể thấy rằng mạng đang có độ chính xác 54%.
Vì có 1/3 cơ hội chọn ngẫu nhiên nhãn chính xác cho một hình ảnh nhất định, biết rằng mạng thực sự học được các mẫu có thể được sử dụng để phân biệt giữa ba lớp.
Nội dung đánh giá chính:
1.Mất đào tạo
2.Mất xác thực
3.Đào tạo chính xác
4.Độ chính xác xác thực
… Đảm bảo rằng có thể dễ dàng phát hiện ra trang bị thừa hoặc trang bị kém trong kết quả .
Bước 8: Đưa ra dự đoán về dữ liệu mới bằng mô hình Keras
Viết chương trình có tên predict.py theo code sau:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
<span style="color: #993300;"><strong># Thêm các thư viện cần thiết</strong></span> <span style="color: #993300;"><strong>from tensorflow.keras.models import load_model</strong></span> <span style="color: #993300;"><strong>import argparse</strong></span> <span style="color: #993300;"><strong>import pickle</strong></span> <span style="color: #993300;"><strong>import cv2</strong></span> <span style="color: #993300;"><strong># xây dựng trình phân tích cú pháp đối số và nhập đọc đối số</strong></span> <span style="color: #993300;"><strong>ap = argparse.ArgumentParser()</strong></span> <span style="color: #993300;"><strong>ap.add_argument("-i", "--image", required=True,</strong></span> <span style="color: #993300;"><strong> help="path to input image we are going to classify")</strong></span> <span style="color: #993300;"><strong>ap.add_argument("-m", "--model", required=True,</strong></span> <span style="color: #993300;"><strong> help="path to trained Keras model")</strong></span> <span style="color: #993300;"><strong>ap.add_argument("-l", "--label-bin", required=True,</strong></span> <span style="color: #993300;"><strong> help="path to label binarizer")</strong></span> <span style="color: #993300;"><strong>ap.add_argument("-w", "--width", type=int, default=28,</strong></span> <span style="color: #993300;"><strong> help="target spatial dimension width")</strong></span> <span style="color: #993300;"><strong>ap.add_argument("-e", "--height", type=int, default=28,</strong></span> <span style="color: #993300;"><strong> help="target spatial dimension height")</strong></span> <span style="color: #993300;"><strong>ap.add_argument("-f", "--flatten", type=int, default=-1,</strong></span> <span style="color: #993300;"><strong> help="whether or not we should flatten the image")</strong></span> <span style="color: #993300;"><strong>args = vars(ap.parse_args())</strong></span> |
trong đó:
–image: Đường dẫn đến hình ảnh đầu vào
– model: đường dẫn mô hình đã đào tạo.
–label-bin: Đường dẫn đến bộ nhãn .
– width: Chiều rộng của hình dạng đầu vào cho CNN
–height: Chiều cao của hình ảnh đầu vào CNN
–flatten: Chúng ta có nên làm phẳng hình ảnh hay không. Theo mặc định, sẽ không làm phẳng hình ảnh. Nếu bạn cần làm phẳng hình ảnh, bạn nên chuyển 1 cho đối số này.
Tiếp theo, hãy tải hình ảnh và thay đổi kích thước dựa trên các đối số dòng lệnh:
|
1 2 3 4 5 6 |
<strong><span style="color: #993300;"># tải hình ảnh đầu vào và thay đổi kích thước nó thành các kích thước theo yêu cầu</span></strong> <strong><span style="color: #993300;">image = cv2.imread(args["image"])</span></strong> <strong><span style="color: #993300;">output = image.copy()</span></strong> <strong><span style="color: #993300;">image = cv2.resize(image, (args["width"], args["height"]))</span></strong> <strong><span style="color: #993300;"># chia tỷ lệ các giá trị pixel thành [0, 1]</span></strong> <strong><span style="color: #993300;">image = image.astype("float") / 255.0</span></strong> |
Và sau đó làm phẳng hình ảnh nếu cần:
|
1 2 3 4 5 6 7 8 |
<strong><span style="color: #993300;"># kiểm tra xem chúng ta có nên làm phẳng hình ảnh và thêm kích thước hàng loạt hay không</span></strong> <strong><span style="color: #993300;">if args["flatten"] > 0:</span></strong> <strong><span style="color: #993300;"> image = image.flatten()</span></strong> <strong><span style="color: #993300;"> image = image.reshape((1, image.shape[0]))</span></strong> <strong><span style="color: #993300;"># nếu không,phải làm việc với CNN - không làm phẳng hình ảnh, chỉ cần thêm kích thước hàng loạt</span></strong> <strong><span style="color: #993300;">else:</span></strong> <strong><span style="color: #993300;"> image = image.reshape((1, image.shape[0], image.shape[1],</span></strong> <strong><span style="color: #993300;"> image.shape[2]))</span></strong> |
Từ đó, hãy tải mô hình + nhãn vào bộ nhớ và đưa ra dự đoán:
|
1 2 3 4 5 6 7 8 9 |
<strong><span style="color: #993300;"># Tải mô hình và nhãn</span></strong> <strong><span style="color: #993300;">print("[INFO] loading network and label binarizer...")</span></strong> <strong><span style="color: #993300;">model = load_model(args["model"])</span></strong> <strong><span style="color: #993300;">lb = pickle.loads(open(args["label_bin"], "rb").read())</span></strong> <strong><span style="color: #993300;"># đưa ra dự đoán trên hình ảnh</span></strong> <strong><span style="color: #993300;">preds = model.predict(image)</span></strong> <strong><span style="color: #993300;"># tìm chỉ mục nhãn lớp với xác suất tương ứng lớn nhất</span></strong> <strong><span style="color: #993300;">i = preds.argmax(axis=1)[0]</span></strong> <strong><span style="color: #993300;">label = lb.classes_[i]</span></strong> |
hiển thị kết quả
|
1 2 3 4 5 6 7 |
<strong><span style="color: #993300;"># vẽ nhãn lớp + xác suất trên hình ảnh đầu ra</span></strong> <strong><span style="color: #993300;">text = "{}: {:.2f}%".format(label, preds[0][i] * 100)</span></strong> <strong><span style="color: #993300;">cv2.putText(output, text, (30, 150), cv2.FONT_HERSHEY_SIMPLEX, 2,</span></strong> <strong><span style="color: #993300;"> (0, 0, 255), 3)</span></strong> <strong><span style="color: #993300;"># hiển thị hình ảnh đầu ra</span></strong> <strong><span style="color: #993300;">cv2.imshow("Image", output)</span></strong> <strong><span style="color: #993300;">cv2.waitKey(0)</span></strong> |
tiến hành chạy câu lệnh theo mẫu sau trong terminal:

|
1 |
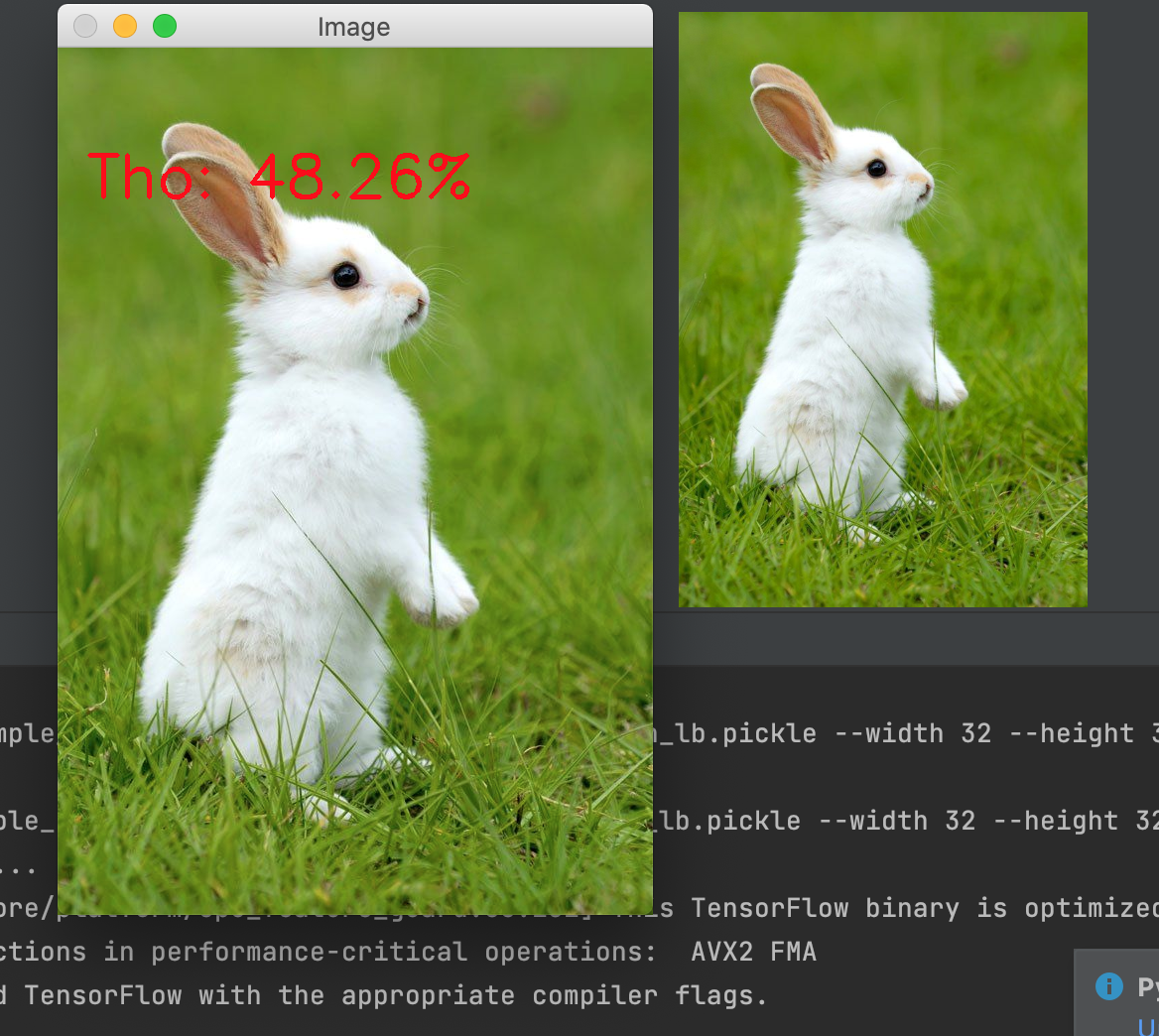
<span style="color: #993300;"><strong>python predict.py --image images/rabit.jpg --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --width 32 --height 32 --flatten 1</strong></span> |
Ta thấy kết quả traing cho mô hình mèo cho kết quả kém nhất, tiến hành test với ảnh chó và thỏ
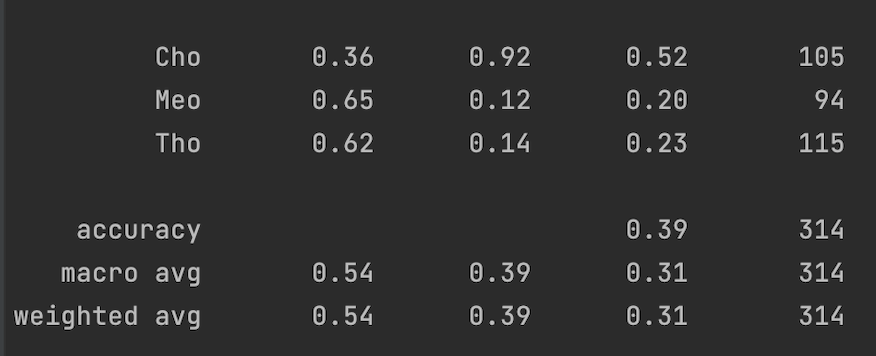
. kết quả như sau