1.Trong lĩnh vực nào AI được sử dụng phổ biến nhất?
a) Ngành y tế
b) Ngành sản xuất
c) Ngành nông nghiệp
d) Ngành dịch vụ
Đáp án đúng: a) Ngành y tế
2.Machine learning là phần nào của AI?
a) Phần cứng
b) Phần mềm
c) Cả hai
d) Không phải là phần nào
Đáp án đúng: b) Phần mềm
3.Deep learning dựa trên mô hình gì để học?
a) Mô hình thống kê
b) Mô hình tuyến tính
c) Mạng neural
d) Mô hình logic
Đáp án đúng: c) Mạng neural
4.Mục đích chính của học máy là gì?
a) Lập trình máy tính để thực hiện các nhiệm vụ cụ thể
b) Huấn luyện máy tính để tự học từ dữ liệu
c) Tạo ra máy tính có trí tuệ nhân tạo
d) Tối ưu hóa các thuật toán máy học
Đáp án đúng: b) Huấn luyện máy tính để tự học từ dữ liệu
5.Mạng neural làm gì trong học sâu?
a) Giảm kích thước dữ liệu
b) Tăng độ chính xác của mô hình
c) Tạo ra mô hình dự đoán
d) Mô phỏng cấu trúc não người
Đáp án đúng: d) Mô phỏng cấu trúc não người
6.Thuật ngữ “overfitting” đề cập đến hiện tượng gì trong machine learning?
a) Mô hình không phù hợp với dữ liệu huấn luyện
b) Mô hình phù hợp tốt với dữ liệu huấn luyện nhưng không tổng quát hóa được cho dữ liệu mới
c) Mô hình không học được từ dữ liệu
d) Mô hình phù hợp tốt với dữ liệu huấn luyện và tổng quát hóa tốt cho dữ liệu mới
Đáp án đúng: b) Mô hình phù hợp tốt với dữ liệu huấn luyện nhưng không tổng quát hóa được cho dữ liệu mới
7.”Bias” trong machine learning là gì?
a) Sai số giữa dự đoán và giá trị thực tế
b) Sự phức tạp của mô hình
c) Tính tổng quát hóa của mô hình
d) Sự khác biệt giữa dữ liệu huấn luyện và dữ liệu kiểm tra
Đáp án đúng: a) Sai số giữa dự đoán và giá trị thực tế
8.Phương pháp “dropout” trong học sâu là gì?
a) Kỹ thuật giảm overfitting bằng cách loại bỏ ngẫu nhiên một số lượng các neuron trong mạng neural trong quá trình huấn luyện
b) Kỹ thuật giảm kích thước của mạng neural
c) Kỹ thuật tăng khả năng học từ dữ liệu mới
d) Kỹ thuật tăng kích thước mạng neural
Đáp án đúng: a) Kỹ thuật giảm overfitting bằng cách loại bỏ ngẫu nhiên một số lượng các neuron trong mạng neural trong quá trình huấn luyện
10.Trong deep learning, “activation function” là gì?
a) Hàm được sử dụng để biến đổi đầu vào của một neural network thành đầu ra
b) Hàm để tính toán gradient
c) Hàm để giảm overfitting
d) Hàm để tối ưu hóa trọng số của mạng neural
Đáp án đúng: a) Hàm được sử dụng để biến đổi đầu vào của một neural network thành đầu ra
11.Trong machine learning, thuật ngữ “unsupervised learning” ám chỉ điều gì?
a) Quá trình học từ dữ liệu được gán nhãn
b) Quá trình học từ dữ liệu không được gán nhãn
c) Quá trình học từ phản hồi từ môi trường
d) Quá trình học từ dữ liệu thô
Đáp án đúng: b) Quá trình học từ dữ liệu không được gán nhãn
12.Trong học máy, “feature” đề cập đến gì?
a) Dữ liệu không được gán nhãn
b) Dữ liệu được gán nhãn
c) Đặc điểm hoặc thuộc tính của dữ liệu
d) Dữ liệu đã được xử lý
Đáp án đúng: c) Đặc điểm hoặc thuộc tính của dữ liệu
13.Trong học máy, “bagging” làm gì?
a) Kỹ thuật tăng kích thước mô hình
b) Kỹ thuật giảm kích thước mô hình
c) Kỹ thuật kết hợp nhiều mô hình dự đoán để cải thiện hiệu suất
d) Kỹ thuật chia tập dữ liệu huấn luyện và kiểm tra
Đáp án đúng: c) Kỹ thuật kết hợp nhiều mô hình dự đoán để cải thiện hiệu suất
14.Phương pháp “boosting” trong machine learning là gì?
a) Kỹ thuật tăng kích thước mô hình
b) Kỹ thuật giảm kích thước mô hình
c) Kỹ thuật kết hợp nhiều mô hình dự đoán để cải thiện hiệu suất
d) Kỹ thuật chia tập dữ liệu huấn luyện và kiểm tra
Đáp án đúng: c) Kỹ thuật kết hợp nhiều mô hình dự đoán để cải thiện hiệu suất
15.AI đã ứng dụng trong lĩnh vực nào sau đây?
a) Dự báo thời tiết
b) Dự đoán giá cổ phiếu
c) Tất cả các phương án trên
d) Không có câu trả lời nào đúng
Đáp án đúng: c) Tất cả các phương án trên
16.Trong học sâu, “convolutional neural networks (CNNs)” thường được sử dụng cho việc gì?
a) Phân loại hình ảnh
b) Phân tích ngôn ngữ tự nhiên
c) Dự đoán chuỗi thời gian
d) Tất cả các phương án trên
Đáp án đúng: a) Phân loại hình ảnh
17.Thuật ngữ “precision” trong machine learning ám chỉ điều gì?
a) Tỷ lệ giữa số lần dự đoán đúng và tổng số lần dự đoán
b) Tỷ lệ giữa số lần dự đoán đúng positive và tổng số positive dự đoán
c) Tỷ lệ giữa số lần dự đoán đúng negative và tổng số negative dự đoán
d) Số lần dự đoán đúng trên tổng số lần dự đoán
Đáp án đúng: b) Tỷ lệ giữa số lần dự đoán đúng positive và tổng số positive dự đoán
18.Thuật ngữ “recall” trong machine learning ám chỉ điều gì?
a) Tỷ lệ giữa số lần dự đoán đúng positive và tổng số positive thực sự
b) Tỷ lệ giữa số lần dự đoán đúng negative và tổng số negative thực sự
c) Số lần dự đoán đúng trên tổng số lần dự đoán
d) Tỷ lệ giữa số lần dự đoán đúng và tổng số lần dự đoán đúng và sai
Đáp án đúng: a) Tỷ lệ giữa số lần dự đoán đúng positive và tổng số positive thực sự
19.Trong học máy, “F1-score” ám chỉ điều gì?
a) Sự kết hợp giữa precision và recall
b) Tổng của precision và recall
c) Tích của precision và recall
d) Tính tổng của số lần dự đoán đúng và số lần dự đoán sai.
Đáp án đúng: c) Tích của precision và recall
20.Thuật ngữ “neural network” trong học máy thường được sử dụng để ám chỉ:
a) Một loại thuật toán tối ưu hóa
b) Một phương pháp tính toán biểu diễn các tầng xử lý thông tin
c) Một loại hàm kích hoạt
d) Một phương pháp gom nhóm dữ liệu
Đáp án đúng: b) Một phương pháp tính toán biểu diễn các tầng xử lý thông tin
21.Thuật ngữ “gradient descent” làm gì trong học máy?
a) Cải thiện độ chính xác của mô hình
b) Tối ưu hóa các tham số của mô hình dựa trên đạo hàm của hàm mất mát
c) Giảm thiểu overfitting trong mô hình
d) Phân tích đặc trưng của dữ liệu
Đáp án đúng: b) Tối ưu hóa các tham số của mô hình dựa trên đạo hàm của hàm mất mát
22.Thuật ngữ “underfitting” trong học máy đề cập đến tình huống nào?
a) Mô hình quá đơn giản và không thể đặc trưng hóa đủ dữ liệu
b) Mô hình phù hợp tốt với dữ liệu huấn luyện nhưng không tổng quát hóa được cho dữ liệu mới
c) Mô hình không học được từ dữ liệu
d) Mô hình phù hợp với dữ liệu huấn luyện và tổng quát hóa tốt cho dữ liệu mới
Đáp án đúng: a) Mô hình quá đơn giản và không thể đặc trưng hóa đủ dữ liệu
23.Đáp án đúng: a) Dự đoán chuỗi thời gianTrong học sâu, “recurrent neural networks (RNNs)” thường được sử dụng cho việc gì?
a) Dự đoán chuỗi thời gian
b) Phân loại hình ảnh
c) Phân tích ngôn ngữ tự nhiên
d) Tất cả các phương án trên
Đáp án đúng: a) Dự đoán chuỗi thời gian
24.Trong học máy, “feature engineering” đề cập đến việc gì?
a) Quá trình chọn lọc các đặc trưng quan trọng từ dữ liệu ban đầu
b) Quá trình xây dựng các mô hình dự đoán
c) Quá trình tinh chỉnh siêu tham số của mô hình
d) Quá trình đánh giá hiệu suất của mô hình
Đáp án đúng: a) Quá trình chọn lọc các đặc trưng quan trọng từ dữ liệu ban đầu
25.”Cross-validation” trong học máy được sử dụng để làm gì?
a) Chia tập dữ liệu thành tập huấn luyện và tập kiểm tra
b) Đánh giá hiệu suất của mô hình trên tập dữ liệu kiểm tra
c) Đánh giá hiệu suất của mô hình và tối ưu hóa siêu tham số
d) Đánh giá độ chính xác của mô hình trên tập dữ liệu huấn luyện
Đáp án đúng: c) Đánh giá hiệu suất của mô hình và tối ưu hóa siêu tham số
26.Trong học sâu, “batch normalization” được sử dụng để giải quyết vấn đề gì?
a) Overfitting
b) Underfitting
c) Gradient vanishing/exploding
d) Biến dạng dữ liệu
Đáp án đúng: c) Gradient vanishing/exploding
27.Trong học máy, thuật ngữ “ensemble learning” ám chỉ điều gì?
a) Việc kết hợp nhiều mô hình dự đoán để cải thiện hiệu suất
b) Sử dụng nhiều tập dữ liệu khác nhau
c) Tạo ra các mô hình phức tạp
d) Chọn lựa siêu tham số tốt nhất cho mô hình
Đáp án đúng: a) Việc kết hợp nhiều mô hình dự đoán để cải thiện hiệu suất
28.”Reinforcement learning” thường được sử dụng trong ngữ cảnh nào?
a) Học có giám sát
b) Học không giám sát
c) Học củng cố
d) Học bán giám sát
Đáp án đúng: c) Học củng cố
29.Trong học máy, “random forest” là một loại gì?
a) Một loại thuật toán tối ưu hóa
b) Một loại mô hình học sâu
c) Một loại mô hình học có giám sát
d) Một phương pháp kết hợp nhiều cây quyết định
Đáp án đúng: d) Một phương pháp kết hợp nhiều cây quyết định
30.Trong học sâu, “backpropagation” được sử dụng để làm gì?
a) Tối ưu hóa các tham số của mạng neural
b) Tăng độ phức tạp của mạng neural
c) Giảm overfitting trong mạng neural
d) Biến đổi đầu vào thành đầu ra cho mạng neural
Đáp án đúng: a) Tối ưu hóa các tham số của mạng neural
31.Trong học máy, “bias-variance tradeoff” ám chỉ điều gì?
a) Sự đánh đổi giữa độ phức tạp của mô hình và khả năng tổng quát hóa
b) Sự đánh đổi giữa độ chính xác và tốc độ của mô hình
c) Sự đánh đổi giữa việc học từ dữ liệu được gán nhãn và không được gán nhãn
d) Sự đánh đổi giữa việc sử dụng các thuật toán khác nhau
Đáp án đúng: a) Sự đánh đổi giữa độ phức tạp của mô hình và khả năng tổng quát hóa
32.”Data preprocessing” trong machine learning đề cập đến việc gì?
a) Việc chọn lọc các đặc trưng quan trọng từ dữ liệu ban đầu
b) Việc xử lý và làm sạch dữ liệu trước khi đưa vào mô hình
c) Tạo ra các mô hình dự đoán từ dữ liệu
d) Đánh giá hiệu suất của mô hình trên dữ liệu kiểm tra
Đáp án đúng: b) Việc xử lý và làm sạch dữ liệu trước khi đưa vào mô hình
33.”Stochastic gradient descent” là gì trong học máy?
a) Một phương pháp tối ưu hóa gradient descent
b) Một phương pháp tối ưu hóa huấn luyện mô hình dựa trên mẫu ngẫu nhiên
c) Một phương pháp tối ưu hóa dựa trên hàm mất mát
d) Một phương pháp tối ưu hóa dựa trên quá trình lan truyền ngược
Đáp án đúng: b) Một phương pháp tối ưu hóa huấn luyện mô hình dựa trên mẫu ngẫu nhiên
34.Trong học máy, “hyperparameter tuning” ám chỉ điều gì?
a) Quá trình tinh chỉnh các siêu tham số của mô hình để cải thiện hiệu suất
b) Quá trình xây dựng các đặc trưng mới từ dữ liệu ban đầu
c) Quá trình giảm kích thước của mô hình
d) Quá trình chia tập dữ liệu thành các phần riêng biệt để đánh giá mô hình
Đáp án đúng: a) Quá trình tinh chỉnh các siêu tham số của mô hình để cải thiện hiệu suất
35.Trong machine learning, “kernel” được sử dụng trong bài toán gì?
a) Regression
b) Classification
c) Clustering
d) Tất cả các phương án trên
Đáp án đúng: d) Tất cả các phương án trên
36.Trong học máy, “feature scaling” thường được sử dụng để làm gì?
a) Tạo ra các đặc trưng mới từ dữ liệu ban đầu
b) Chọn lọc các đặc trưng quan trọng từ dữ liệu ban đầu
c) Chuẩn hóa dữ liệu đầu vào để đảm bảo mô hình hoạt động hiệu quả
d) Đánh giá hiệu suất của mô hình trên tập dữ liệu kiểm tra
Đáp án đúng: c) Chuẩn hóa dữ liệu đầu vào để đảm bảo mô hình hoạt động hiệu quả
37.”K-means” là một thuật toán phân cụm được sử dụng trong lĩnh vực nào?
a) Regression
b) Classification
c) Clustering
d) Tất cả các phương án trên
Đáp án đúng: c) Clustering
38.Trong machine learning, thuật ngữ “kernel trick” ám chỉ điều gì?
a) Sự chuyển đổi của dữ liệu thành một không gian chiều cao hơn để giải quyết vấn đề phân loại phi tuyến
b) Sự chọn lọc các đặc trưng quan trọng từ dữ liệu ban đầu
c) Sự giảm chiều dữ liệu để tăng tốc độ huấn luyện
d) Sự tăng kích thước của mô hình để cải thiện hiệu suất
Đáp án đúng: a) Sự chuyển đổi của dữ liệu thành một không gian chiều cao hơn để giải quyết vấn đề phân loại phi tuyến
39.Trong học máy, “loss function” (hàm mất mát) được sử dụng để làm gì?
a) Đánh giá hiệu suất của mô hình trên tập dữ liệu huấn luyện
b) Đánh giá hiệu suất của mô hình trên tập dữ liệu kiểm tra
c) Đo lường sai số giữa dự đoán và giá trị thực tế
d) Tất cả các phương án trên
Đáp án đúng: c) Đo lường sai số giữa dự đoán và giá trị thực tế
40.”Outlier detection” trong machine learning ám chỉ điều gì?
a) Quá trình phát hiện và loại bỏ dữ liệu bất thường khỏi tập huấn luyện
b) Quá trình tạo ra dữ liệu mới từ dữ liệu hiện có
c) Quá trình chuyển đổi dữ liệu để tăng độ chính xác của mô hình
d) Quá trình đánh giá hiệu suất của mô hình trên tập dữ liệu kiểm tra
Đáp án đúng: a) Quá trình phát hiện và loại bỏ dữ liệu bất thường khỏi tập huấn luyện
41.Trong học máy, “early stopping” được sử dụng để giải quyết vấn đề gì?
a) Overfitting
b) Underfitting
c) Gradient vanishing/exploding
d) Biến dạng dữ liệu
Đáp án đúng: a) Overfitting
42.Trong học sâu, “batch size” là gì?
a) Số lượng mẫu dữ liệu được sử dụng để cập nhật các trọng số trong mỗi lần lan truyền ngược
b) Kích thước của các tầng ẩn trong mạng neural
c) Số lượng các mẫu dữ liệu được sử dụng trong quá trình huấn luyện mạng neural
d) Số lượng epoch cần thiết để đạt được hiệu suất mong muốn
Đáp án đúng: c) Số lượng các mẫu dữ liệu được sử dụng trong quá trình huấn luyện mạng neural
43.Trong học máy, “dimensionality reduction” được sử dụng để làm gì?
a) Giảm số chiều của dữ liệu để giảm độ phức tạp của mô hình
b) Tăng số chiều của dữ liệu để cải thiện hiệu suất của mô hình
c) Chọn lọc các đặc trưng quan trọng từ dữ liệu ban đầu
d) Tạo ra các đặc trưng mới từ dữ liệu ban đầu
Đáp án đúng: a) Giảm số chiều của dữ liệu để giảm độ phức tạp của mô hình
44.Trong học máy, “gradient boosting” là gì?
a) Một kỹ thuật tối ưu hóa gradient descent
b) Một phương pháp học có giám sát kết hợp nhiều mô hình yếu để tạo ra một mô hình mạnh
c) Một phương pháp tối ưu hóa dựa trên hàm mất mát
d) Một kỹ thuật tạo ra các đặc trưng mới từ dữ liệu ban đầu
Đáp án đúng: b) Một phương pháp học có giám sát kết hợp nhiều mô hình yếu để tạo ra một mô hình mạnh
45.Trong học máy, “k-means clustering” được sử dụng cho mục đích gì?
a) Phân loại hình ảnh
b) Phân cụm dữ liệu không gán nhãn vào các nhóm dựa trên đặc trưng tương tự
c) Dự đoán chuỗi thời gian
d) Phân tích ngôn ngữ tự nhiên
Đáp án đúng: b) Phân cụm dữ liệu không gán nhãn vào các nhóm dựa trên đặc trưng tương tự
46.Trong học sâu, “ReLu” là viết tắt của điều gì?
a) Rectified Linear Unit
b) Randomized Learning Unit
c) Recursive Linear Unit
d) Regularized Learning Unit
Đáp án đúng: a) Rectified Linear Unit
47.”F1 score” được sử dụng trong machine learning để đo lường điều gì?
a) Precision và recall
b) Bias và variance
c) Feature và label
d) Epoch và batch size
Đáp án đúng: a) Precision và recall
48.Trong học sâu, “LSTM” là viết tắt của điều gì?
a) Long Short-Term Memory
b) Linear Sequential Memory
c) Learning Stateful Memory
d) Layered Short-Term Memory
Đáp án đúng: a) Long Short-Term Memory
49.”Principal Component Analysis (PCA)” được sử dụng trong machine learning để làm gì?
a) Giảm số chiều của dữ liệu bằng cách chuyển đổi các biến ban đầu thành các biến mới không tương quan
b) Phân loại hình ảnh
c) Dự đoán chuỗi thời gian
d) Phân tích ngôn ngữ tự nhiên
Đáp án đúng: a) Giảm số chiều của dữ liệu bằng cách chuyển đổi các biến ban đầu thành các biến mới không tương quan
50.”Word embedding” trong học sâu được sử dụng cho mục đích gì?
a) Biểu diễn từ dưới dạng các vector số thực
b) Phân loại hình ảnh
c) Dự đoán chuỗi thời gian
d) Phân tích ngôn ngữ tự nhiên
Đáp án đúng: a) Biểu diễn từ dưới dạng các vector số thực
51.”AdaBoost” là một thuật toán thuộc loại gì?
a) K-means clustering
b) Supervised learning
c) Unsupervised learning
d) Ensemble learning
Đáp án đúng: d) Ensemble learning
52.Trong học sâu, “softmax” làm gì?
a) Biến đổi đầu ra của mạng neural thành xác suất
b) Tăng độ phức tạp của mạng neural
c) Giảm overfitting trong mạng neural
d) Biến đổi đầu vào thành đầu ra cho mạng neural
Đáp án đúng: a) Biến đổi đầu ra của mạng neural thành xác suất
53.”K-fold cross-validation” được sử dụng để làm gì?
a) Chia tập dữ liệu thành tập huấn luyện và tập kiểm tra
b) Đánh giá hiệu suất của mô hình trên tập dữ liệu kiểm tra
c) Đánh giá hiệu suất của mô hình và tối ưu hóa siêu tham số
d) Đánh giá độ chính xác của mô hình trên tập dữ liệu huấn luyện
Đáp án đúng: c) Đánh giá hiệu suất của mô hình và tối ưu hóa siêu tham số
54.Trong học máy, thuật ngữ “feature extraction” ám chỉ điều gì?
a) Quá trình chọn lọc các đặc trưng quan trọng từ dữ liệu ban đầu.
b) Quá trình tạo ra các mô hình phức tạp hơn để đối phó với dữ liệu phức tạp.
c) Quá trình biến đổi dữ liệu đầu vào thành dạng phù hợp để huấn luyện mô hình.
d) Quá trình trích xuất thông tin quan trọng từ dữ liệu và biến đổi chúng thành các đặc trưng mới.
Đáp án đúng: d) Quá trình trích xuất thông tin quan trọng từ dữ liệu và biến đổi chúng thành các đặc trưng mới.
55.Trong học máy, “k-nearest neighbors (k-NN)” là một loại gì?
a) Một loại mô hình học sâu.
b) Một loại mô hình học có giám sát.
c) Một thuật toán phân loại.
d) Một phương pháp học không giám sát.
Đáp án đúng: d) Một phương pháp học không giám sát
56.Trong học máy, “logistic regression” là một loại gì?
a) Một loại mô hình học sâu.
b) Một loại mô hình học có giám sát.
c) Một thuật toán phân loại.
d) Một phương pháp học không giám sát.
Đáp án đúng: c) Một thuật toán phân loại.
57.Trong học máy, “decision tree” là một loại gì?
a) Một loại mô hình học sâu.
b) Một loại mô hình học có giám sát.
c) Một thuật toán phân loại.
d) Một phương pháp học không giám sát.
Đáp án đúng: b) Một loại mô hình học có giám sát.
58.Trong học máy, “support vector machine (SVM)” là một loại gì?
a) Một loại mô hình học sâu.
b) Một loại mô hình học có giám sát.
c) Một thuật toán phân loại.
d) Một phương pháp học không giám sát.
Đáp án đúng: b) Một loại mô hình học có giám sát.
59.Trong học máy, thuật ngữ “hyperparameter” ám chỉ điều gì?
a) Các tham số mà mô hình học từ dữ liệu.
b) Các tham số không thể thay đổi được trong quá trình huấn luyện mô hình.
c) Các tham số được thiết lập trước cho mô hình và không thay đổi dựa trên dữ liệu.
d) Các tham số quyết định cách mà mô hình được huấn luyện và tối ưu hóa.
Đáp án đúng: d) Các tham số quyết định cách mà mô hình được huấn luyện và tối ưu hóa.
60.Trong học máy, thuật ngữ “gradient descent” ám chỉ điều gì?
a) Một thuật toán tối ưu hóa được sử dụng để cập nhật các tham số của mô hình để giảm thiểu hàm mất mát.
b) Quá trình tăng độ phức tạp của mô hình để tăng hiệu suất.
c) Quá trình chuyển đổi dữ liệu đầu vào thành dạng phù hợp cho mạng neural.
d) Quá trình chia tách dữ liệu thành các phần nhỏ để đánh giá mô hình.
Đáp án đúng: a) Một thuật toán tối ưu hóa được sử dụng để cập nhật các tham số của mô hình để giảm thiểu hàm mất mát.
61.Trong học máy, “batch size” là gì?
a) Số lượng mẫu dữ liệu được sử dụng để cập nhật các tham số của mô hình trong mỗi lần lặp.
b) Số lượng lớp trong một mô hình neural network.
c) Số lượng neurons trong một lớp của mạng neural.
d) Số lượng epochs được sử dụng trong quá trình huấn luyện.
Đáp án đúng: a) Số lượng mẫu dữ liệu được sử dụng để cập nhật các tham số của mô hình trong mỗi lần lặp.
62.Trong học máy, “accuracy” là gì?
a) Tỉ lệ số lần mô hình dự đoán đúng trên tổng số mẫu dữ liệu.
b) Số lượng dữ liệu được sử dụng để huấn luyện mô hình.
c) Số lượng đặc trưng của mỗi mẫu dữ liệu.
d) Tổng số lần lặp trong quá trình huấn luyện mô hình.
Đáp án đúng: a) Tỉ lệ số lần mô hình dự đoán đúng trên tổng số mẫu dữ liệu.
63.Trong học máy, “confusion matrix” là gì?
a) Một bảng tổng hợp thể hiện kết quả của mô hình dự đoán so với nhãn thực tế.
b) Một phương pháp để giảm kích thước của dữ liệu đầu vào.
c) Một phương pháp để xử lý dữ liệu bị thiếu.
d) Một phương pháp để chọn lọc các đặc trưng quan trọng từ dữ liệu.
Đáp án đúng: a) Một bảng tổng hợp thể hiện kết quả của mô hình dự đoán so với nhãn thực tế.
64.Trong học máy, “cross-validation” là gì?
a) Một kỹ thuật chia tập dữ liệu thành các tập con để đánh giá hiệu suất của mô hình.
b) Một phương pháp để chọn lọc các đặc trưng quan trọng từ dữ liệu.
c) Một phương pháp để xử lý dữ liệu bị thiếu.
d) Một phương pháp để giảm kích thước của dữ liệu đầu vào.
Đáp án đúng: a) Một kỹ thuật chia tập dữ liệu thành các tập con để đánh giá hiệu suất của mô hình.
65.Trong học máy, thuật ngữ “variance” ám chỉ điều gì?
a) Sự chệch của mô hình so với dữ liệu thực tế.
b) Một thành phần của mô hình thể hiện độ phức tạp của nó.
c) Sự phù hợp của mô hình với dữ liệu huấn luyện.
d) Sự không ổn định của mô hình khi áp dụng cho dữ liệu mới.
Đáp án đúng: d) Sự không ổn định của mô hình khi áp dụng cho dữ liệu mới.
66.Trong học máy, thuật ngữ “regularization” ám chỉ điều gì?
a) Quá trình giảm kích thước của mô hình để giảm overfitting.
b) Quá trình tăng độ phức tạp của mô hình để tăng hiệu suất.
c) Quá trình chia tập dữ liệu thành các phần nhỏ để đánh giá mô hình.
d) Quá trình tạo ra các mô hình phức tạp hơn để đối phó với dữ liệu phức tạp.
Đáp án đúng: a) Quá trình giảm kích thước của mô hình để giảm overfitting.
67.Trong học máy, “grid search” là gì?
a) Một kỹ thuật tìm kiếm siêu tham số tốt nhất cho mô hình bằng cách thử tất cả các giá trị trong một lưới.
b) Một phương pháp để giảm kích thước của dữ liệu đầu vào.
c) Một phương pháp để tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu.
d) Một phương pháp tối ưu hóa cho mô hình học sâu.
Đáp án đúng: a) Một kỹ thuật tìm kiếm siêu tham số tốt nhất cho mô hình bằng cách thử tất cả các giá trị trong một lưới.
68.Trong học máy, thuật ngữ “pipeline” ám chỉ điều gì?
a) Một chuỗi các bước xử lý dữ liệu hoặc mô hình hóa được kết hợp trong một quy trình duy nhất.
b) Một phương pháp tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu.
c) Một phương pháp để tối ưu hóa các tham số của mô hình.
d) Một phương pháp để giảm kích thước của dữ liệu đầu vào.
Đáp án đúng: a) Một chuỗi các bước xử lý dữ liệu hoặc mô hình hóa được kết hợp trong một quy trình duy nhất.
69.Trong học máy, thuật ngữ “bag-of-words” (BoW) là gì?
a) Một phương pháp biểu diễn văn bản thành một tập hợp không có thứ tự của các từ và số lượng của chúng.
b) Một phương pháp để giảm kích thước của dữ liệu đầu vào.
c) Một phương pháp tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu.
d) Một phương pháp để chia tập dữ liệu thành các tập con để đánh giá mô hình.
Đáp án đúng: a) Một phương pháp biểu diễn văn bản thành một tập hợp không có thứ tự của các từ và số lượng của chúng.
70.Trong học máy, “data augmentation” là gì?
a) Một phương pháp tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu bằng cách thêm các biến thể nhỏ.
b) Một phương pháp để giảm kích thước của dữ liệu đầu vào.
c) Một phương pháp tối ưu hóa cho mô hình học sâu.
d) Một phương pháp để chuyển đổi dữ liệu đầu vào thành dạng phù hợp cho mạng neural.
Đáp án đúng: a) Một phương pháp tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu bằng cách thêm các biến thể nhỏ.
71.Trong học máy, “dropout” là gì?
a) Một kỹ thuật sử dụng để giảm kích thước của dữ liệu đầu vào.
b) Một phương pháp tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu.
c) Một kỹ thuật chính regularize trong mạng neural network bằng cách ngẫu nhiên loại bỏ một số đơn vị trong quá trình huấn luyện.
d) Một phương pháp để chuyển đổi dữ liệu đầu vào thành dạng phù hợp cho mạng neural.
Đáp án đúng: c) Một kỹ thuật chính regularize trong mạng neural network bằng cách ngẫu nhiên loại bỏ một số đơn vị trong quá trình huấn luyện.
72.Trong học máy, “batch normalization” là gì?
a) Một kỹ thuật sử dụng để giảm kích thước của dữ liệu đầu vào.
b) Một phương pháp tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu.
c) Một kỹ thuật chuẩn hóa dữ liệu đầu ra từ các lớp trước trong mạng neural network.
d) Một phương pháp để chuyển đổi dữ liệu đầu vào thành dạng phù hợp cho mạng neural.
Đáp án đúng: c) Một kỹ thuật chuẩn hóa dữ liệu đầu ra từ các lớp trước trong mạng neural network.
73.Trong học máy, thuật ngữ “ReLU” là gì?
a) Một thuật toán tối ưu hóa được sử dụng để cập nhật các tham số của mô hình để giảm thiểu hàm mất mát.
b) Một phương pháp biểu diễn từng từ trong văn bản thành một vector số.
c) Một hàm kích hoạt phổ biến trong mạng neural network, được định nghĩa bởi f(x) = max(0, x).
d) Một phương pháp để chuyển đổi dữ liệu đầu vào thành dạng phù hợp cho mạng neural.
Đáp án đúng: c) Một hàm kích hoạt phổ biến trong mạng neural network, được định nghĩa bởi f(x) = max(0, x).
74.Trong học máy, “backpropagation” là gì?
a) Một kỹ thuật để chuyển đổi dữ liệu đầu vào thành dạng phù hợp cho mạng neural.
b) Một phương pháp tối ưu hóa cho mô hình học sâu.
c) Một thuật toán được sử dụng để lan truyền ngược thông tin gradient qua mạng neural network để cập nhật các trọng số.
d) Một phương pháp tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu.
Đáp án đúng: c) Một thuật toán được sử dụng để lan truyền ngược thông tin gradient qua mạng neural network để cập nhật các trọng số.
75.Trong học máy, “epoch” là gì?
a) Một số lượng mẫu dữ liệu được sử dụng để cập nhật các trọng số của mạng neural network.
b) Một phương pháp để chuyển đổi dữ liệu đầu vào thành dạng phù hợp cho mạng neural.
c) Một số lần lặp lại toàn bộ tập dữ liệu trong quá trình huấn luyện mô hình.
d) Một phương pháp tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu.
Đáp án đúng: c) Một số lần lặp lại toàn bộ tập dữ liệu trong quá trình huấn luyện mô hình.0
76.Trong học máy, “early stopping” là gì?
a) Một kỹ thuật tăng số lượng lớp trong một mạng neural network.
b) Một kỹ thuật dừng quá trình huấn luyện mô hình khi hiệu suất trên tập kiểm tra bắt đầu giảm.
c) Một kỹ thuật để tối ưu hóa các tham số của mô hình.
d) Một kỹ thuật sử dụng để giảm kích thước của dữ liệu đầu vào.
Đáp án đúng: b) Một kỹ thuật dừng quá trình huấn luyện mô hình khi hiệu suất trên tập kiểm tra bắt đầu giảm.
77.Trong học máy, “validation set” là gì?
a) Một tập dữ liệu được sử dụng để đánh giá hiệu suất của mô hình trong quá trình huấn luyện.
b) Một phương pháp tối ưu hóa cho mô hình học sâu.
c) Một tập dữ liệu được sử dụng để kiểm tra hiệu suất cuối cùng của mô hình sau khi huấn luyện.
d) Một phương pháp để tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu.
Đáp án đúng: a) Một tập dữ liệu được sử dụng để đánh giá hiệu suất của mô hình trong quá trình huấn luyện.
78.Trong học máy, “cross-entropy loss” là gì?
a) Một hàm mất mát thường được sử dụng trong bài toán phân loại, tính toán sự chênh lệch giữa phân phối dự đoán và phân phối thực tế của các lớp.
b) Một phương pháp để tạo ra các mẫu dữ liệu mới từ dữ liệu ban đầu.
c) Một phương pháp để chuyển đổi dữ liệu đầu vào thành dạng phù hợp cho mạng neural.
d) Một kỹ thuật tối ưu hóa cho mô hình học sâu.
Đáp án đúng: a) Một hàm mất mát thường được sử dụng trong bài toán phân loại, tính toán sự chênh lệch giữa phân phối dự đoán và phân phối thực tế của các lớp.
78.Trong học máy, “mean squared error (MSE)” là gì?
a) Một phương pháp để tối ưu hóa các tham số của mô hình.
b) Một hàm mất mát thường được sử dụng trong bài toán phân loại, đo lường sự khác biệt giữa dự đoán và giá trị thực tế.
c) Một phương pháp để chuyển đổi dữ liệu đầu vào thành dạng phù hợp cho mạng neural.
d) Một hàm mất mát thường được sử dụng trong bài toán hồi quy, tính toán bình phương của sự chênh lệch giữa dự đoán và giá trị thực tế.
Đáp án đúng: d) Một hàm mất mát thường được sử dụng trong bài toán hồi quy, tính toán bình phương của sự chênh lệch giữa dự đoán và giá trị thực tế.
79.Trong học máy, “learning rate” là gì?
a) Mức độ quan trọng của mỗi đặc trưng trong việc xác định kết quả dự đoán của mô hình.
b) Tốc độ mà mô hình học từ dữ liệu huấn luyện, tỉ lệ cập nhật các tham số của mạng neural.
c) Số lượng lớn nhất của mẫu dữ liệu được sử dụng trong một epoch.
d) Số lượng mẫu dữ liệu được sử dụng để đánh giá hiệu suất của mô hình trong quá trình huấn luyện.
Đáp án đúng: b) Tốc độ mà mô hình học từ dữ liệu huấn luyện, tỉ lệ cập nhật các tham số của mạng neural.
80.Trong học máy, “momentum” là gì?
a) Một phương pháp để tối ưu hóa các tham số của mô hình.
b) Một kỹ thuật tối ưu hóa cho mô hình học sâu.
c) Một hệ số giúp điều chỉnh tốc độ học của mô hình trong quá trình lan truyền ngược.
d) Một phương pháp để chuyển đổi dữ liệu đầu vào thành dạng phù hợp cho mạng neural.
Đáp án đúng: c) Một hệ số giúp điều chỉnh tốc độ học của mô hình trong quá trình lan truyền ngược.
81.Thuật toán K-means thuộc loại bài toán nào sau đây?
A) Học có giảm sát
B) Học không giám sát
C) Học tăng cường
D) Học bán giám sát
Đáp án: B) Học không giám sát
82.Câu hỏi: Trong học máy, để giảm số chiều của dữ liệu mà vẫn giữ được các đặc trưng quan trọng, ta thường sử dụng phương pháp nào?
A) Principal Component Analysis (PCA)
B) K-Means Clustering
C) Support Vector Machine (SVM)
D) Decision Trees
Đáp án: A) Principal Component Analysis (PCA)
83.Câu hỏi: Trong học máy, thuật toán nào được sử dụng để tìm cực trị của hàm mất mát?
A) Gradient Descent
B) K-Means Clustering
C) Decision Trees
D) K-Nearest Neighbors
Đáp án: A) Gradient Descent
84.Câu hỏi: Trong mô hình mạng nơ-ron nhân tạo (ANN), hàm activation function sigmoid có giá trị thuộc khoảng nào?
A) (-1, 1)
B) (0, 1)
C) (-∞, +∞)
D) [0, 1]
Đáp án: B) (0, 1)
86.Câu hỏi: Trong mô hình mạng nơ-ron, đạo hàm của hàm sigmoid được tính như thế nào?
A) σ(s)(1 – σ(s))
B) σ(s) – (1 – σ(s))
C) σ(s)
D) 1 – σ(s)
Đáp án: A) σ(s)(1 – σ(s))
87.Câu hỏi: Đối với thuật toán K-Means, việc chọn số lượng cụm (clusters) thích hợp được gọi là gì?
A) Elbow method
B) Gradient Descent
C) Confusion Matrix
D) Silhouette Analysis
Đáp án: A) Elbow method
88.Câu hỏi: Trong mô hình Linear Regression, hệ số hồi quy (regression coefficients) được tính như thế nào?
A) Bằng cách giải phương trình đạo hàm của hàm mất mát
B) Bằng cách chia tổng của đầu ra cho tổng của đầu vào
C) Bằng cách tối ưu hàm mất mát bằng Gradient Descent
D) Bằng cách tính đạo hàm riêng của từng biến đầu vào
Đáp án: C) Bằng cách tối ưu hàm mất mát bằng Gradient Descent
89.Câu hỏi: Trong mạng nơ-ron, layer nào thường được sử dụng để giảm kích thước của đầu vào?
A) Activation layer
B) Dropout layer
C) Pooling layer
D) Dense layer
Đáp án: C) Pooling layer
90.Câu hỏi: Trong mô hình Random Forest, việc chọn feature cho mỗi cây con được thực hiện như thế nào?
A) Tất cả các feature đều được chọn
B) Chỉ một subset ngẫu nhiên của các feature được chọn
C) Chỉ feature có độ quan trọng cao được chọn
D) Feature được chọn dựa trên tần suất xuất hiện trong dữ liệu huấn luyện
Đáp án: B) Chỉ một subset ngẫu nhiên của các feature được chọn
91.Câu hỏi: Trong học máy, độ đo nào thường được sử dụng để đánh giá hiệu suất của mô hình phân loại?
A) R2 Score
B) Mean Absolute Error (MAE)
C) Confusion Matrix
D) Root Mean Squared Error (RMSE)
Đáp án: C) Confusion Matrix
92.Câu hỏi: Trong mạng nơ-ron, hàm activation function nào thường được sử dụng để xử lý các vấn đề phân loại nhị phân?
A) Sigmoid
B) Tanh
C) ReLU
D) Leaky ReLU
Đáp án: A) Sigmoid
93.Câu hỏi: Thuật toán K-means được sử dụng cho mục đích gì trong học máy?
A) Phân loại
B) Hồi quy
C) Gom cụm
D) Phân tích dữ liệu thô
Đáp án: C) Gom cụm
94.Câu hỏi: Trong học máy, phương pháp nào được sử dụng để giảm số chiều của dữ liệu mà vẫn giữ được các đặc trưng quan trọng?
A) Principal Component Analysis (PCA)
B) Linear Discriminant Analysis (LDA)
C) Support Vector Machine (SVM)
D) Naive Bayes Classifier
Đáp án: A) Principal Component Analysis (PCA)
95.Câu hỏi: Trong học máy, điều gì xảy ra khi một mô hình bị overfitting?
A) Mô hình phản ứng quá mức với dữ liệu huấn luyện
B) Mô hình không đủ phức tạp để hiểu dữ liệu
C) Mô hình không thể học từ dữ liệu
D) Mô hình không thể tổng quát hóa từ dữ liệu
Đáp án: A) Mô hình phản ứng quá mức với dữ liệu huấn luyện
96.Câu hỏi: Trong học máy, để giảm thiểu hiện tượng overfitting, ta có thể thực hiện các biện pháp nào sau đây?
A) Sử dụng kích thước batch lớn
B) Sử dụng learning rate nhỏ
C) Thêm dữ liệu huấn luyện
D) Tăng số lượng epoch
Đáp án: C) Thêm dữ liệu huấn luyện
97.Câu hỏi: Trong mạng nơ-ron, hàm activation function ReLU (Rectified Linear Unit) có đặc điểm gì?
A) Nó làm giảm độ chệch (bias) của mô hình
B) Nó giữ nguyên giá trị âm
C) Nó không bị sự mất mát gradient khi huấn luyện
D) Nó không thể giải quyết được vấn đề overfitting
Đáp án: C) Nó không bị sự mất mát gradient khi huấn luyện
98.Câu hỏi: Trong học máy, phương pháp nào được sử dụng để đánh giá hiệu suất của một mô hình?
A) Accuracy
B) Precision
C) Recall
D) F1-score
Đáp án: A) Accuracy
99.Câu hỏi: Trong mạng nơ-ron, hàm softmax thường được sử dụng ở tầng nào?
A) Tầng input
B) Tầng hidden
C) Tầng output
D) Tầng convolutional
Đáp án: C) Tầng output
100.Câu hỏi: Trong học máy, thuật toán nào sau đây được sử dụng để giải quyết bài toán phân loại?
A) K-means
B) Linear Regression
C) Decision Tree
D) KNN (K-Nearest Neighbors)
Đáp án: C) Decision Tree
101.Câu hỏi: Trong học máy, để giảm thiểu hiện tượng underfitting, ta có thể thực hiện các biện pháp nào sau đây?
A) Tăng số lượng epoch
B) Sử dụng learning rate lớn
C) Thêm dữ liệu huấn luyện
D) Giảm số lượng epoch
Đáp án: C) Thêm dữ liệu huấn luyện
102.Câu hỏi: Trong mạng nơ-ron hồi quy (RNN), đối với bài toán dự đoán chuỗi thời gian, đặc điểm chính của mạng LSTM (Long Short-Term Memory) là gì?
A) Khả năng hiểu được thông tin ngắn hạn
B) Khả năng ghi nhớ thông tin dài hạn
C) Khả năng xử lý chuỗi với độ dài biến đổi
D) Khả năng giảm thiểu hiện tượng overfitting
103.Câu hỏi: Trong học máy, để đánh giá hiệu suất của một mô hình phân loại, chúng ta thường sử dụng các phép đo nào sau đây?
A) Accuracy, Precision, Recall
B) Mean Squared Error, Root Mean Squared Error
C) Mean Absolute Error, R-squared
D) F1-score, ROC-AUC
Đáp án: A) Accuracy, Precision, Recall
104.Câu hỏi: Trong Python, thư viện nào sau đây được sử dụng phổ biến nhất cho việc xử lý dữ liệu số và tính toán khoa học?
A) TensorFlow
B) Scikit-learn
C) Pandas
D) Matplotlib
Đáp án: C) Pandas
105.Câu hỏi: Trong học máy, để tìm ra giải pháp tối ưu cho một bài toán cụ thể, chúng ta thường sử dụng thuật toán nào sau đây?
A) Random Forest
B) Gradient Descent
C) K-means Clustering
D) Naive Bayes
Đáp án: B) Gradient Descent
106.Câu hỏi: Trong mạng nơ-ron nhân tạo, hàm activation nào được sử dụng phổ biến nhất cho lớp ẩn?
A) Sigmoid
B) Tanh
C) ReLU (Rectified Linear Unit)
D) Softmax
Đáp án: C) ReLU (Rectified Linear Unit)
107.Câu hỏi: Trong mạng nơ-ron tích chập (CNN), tầng nào thường được sử dụng để giảm kích thước không gian của dữ liệu đầu vào?
A) Fully Connected Layer
B) Pooling Layer
C) Convolutional Layer
D) Dropout Layer
Đáp án: B) Pooling Layer
108.Câu hỏi: Trong học máy, khi sử dụng thuật toán K-means Clustering, số lượng cụm cần phải xác định trước hay được xác định dựa trên dữ liệu đầu vào?
A) Số lượng cụm cần phải xác định trước
B) Số lượng cụm được xác định dựa trên dữ liệu đầu vào
C) Không cần quan tâm đến số lượng cụm
D) Số lượng cụm được xác định bởi các tham số ngẫu nhiên
Đáp án: A) Số lượng cụm cần phải xác định trước
109.Kết quả đoạn code sau là gì
T = (1, 2, 3, 1, 5, 3, 3, 2)
x = T.index(3)
print(x)
A) 2
B) 5
C) 6
D) 3
Đáp án: C) 6
110.Cho danh sách L1 = [1, 3, 2, 1, 3, 4, 3]. Đoạn code nào dưới đây tạo danh L2 = [1, 3, 2, 4] là các phần tử của L1 và không lấy lặp
A) L2 = numpy.remove_duplicate(L1)
B) L2 = L1.remove_duplicate()
C) L2 = list.remove_duplicate(L1)
D) L2 = list(set(L1))
Đáp án: D) L2 = list(set(L1))
111.Đâu không phải là kiểu lỗi được xây dựng sẵn trong Python
A) EOFError
B) IndexError
C) KeyError
D) LoopError
Đáp án: D) LoopError
112,Để nạp chồng toán tử ==, phương thức nào cần thực hiện
A) comp()
B) eq()
C) equal()
D) ne()
Đáp án: B) eq()
113.Cách tạo phương thức tĩnh trong Python
A) Sử dụng hàm static()
B) Sử dụng chỉ dẫn @staticmethod
C) Sử dụng chỉ dẫn @classmethod
D) Python không có phương thức tĩnh
Đáp án: B) Sử dụng chỉ dẫn @staticmethod
114.Câu lệnh sau là gì
f = open(“”C:\MyFile.txt””, ‘+’)”
A) Mở tệp và cho phép bổ sung vào cuối tệp
B) Mở tệp để đọc hoặc ghi
C) Mở tệp để đọc
D) Mở tệp để ghi
Đáp án: A) Mở tệp và cho phép bổ sung vào cuối tệp
115.Giả sử x là tập dữ liệu hai chiều (samples, features). Cần chuẩn hóa các giá trị của đặc trưng về dạng có giá trị trung bình bằng 0 (a mean of 0) và có độ lệch chuẩn bằng 1 (a standard deviation of 1). Phương án nào dưới đây đạp ứng yêu cầu
A) “x = x / x.mean(axis=1)
x = x / x.std(axis=1)”
B) “x = x / x.mean(axis=0)
x = x / x.std(axis=0)”
C) “x = x – x.mean(axis=0)
x = x / x.std(axis=0)”
D) “x = x – x.mean(axis=1)
x = x / x.std(axis=0)”
Đáp án: B) “x = x / x.mean(axis=0)
x = x / x.std(axis=0)”
116.Hàm nào thực hiện tính trung vị cho mảng X sau
X = numpy.array([5, np.nan, 7, 9)”
A) numpy.nan_median()
B) numpy.median()
C) numpy.mediannan()
D) numpy.nanmedian()
Đáp án: D) numpy.nanmedian()
117.Kết quả nào đúng cho đoạn code sau
X = numpy.array([[3, 89],
[23, 17],
[92, 26]
[34, 28]
[12, 9]])
print(numpy.ptp(X))”
A) 3
B) 92
C) 89
D) Error
Đáp án: C) 89
118.Đâu không phải thuộc tính của module
A) file
B) name
C) dict
D) list
Đáp án: D) list
119.Xác định kết quả cho đoạn code sau:
import collections
c = collections.Counter([1, 2, 2, 3, 3, 4, 4, 4, 4, 5])
print(c.most_common(1))”
A) [(4, 4)]
B) [(2, 2)]
C) [(4, 4), (2, 2)]
D) Error
Đáp án: A) [(4, 4)]
120.Đâu là kết quả của đoạn code sau:
colors = {1: ‘blue’, 2: ‘red’, 3: ‘green’}
itm = colors.items()
print(itm)”
A) dict_items([(1, ‘blue’), (2, ‘red’), (3, ‘green’)])
B) dict_items([(‘blue’), (‘red’), (‘green’)])
C) [(1, ‘blue’), (2, ‘red’), (3, ‘green’)]
D) [(‘blue’), (‘red’), (‘green’)]
Đáp án: A) dict_items([(1, ‘blue’), (2, ‘red’), (3, ‘green’)])
121.Khẳng định nào đúng
1-Tăng số đặc trưng không làm tăng số mẫu huấn luyện
2-Tăng đặc trưng không làm ảnh hưởng tới hiệu năng của hệ thống
3-Tăng đặc trưng không luôn luôn tăng độ chính xác của phân lớp”
A) 1 và 3
B) 2 và 3
C) 3
D) 1 và 2
Đáp án: A) 1 và 3
122.Tìm kiếm đặc trưng theo chiến lược vét cạn có đặc điểm gì
A) Không tìm được tập đặc trưng con tối ưu
B) Luôn tìm được tập đặc trưng con tối ưu
C) Chỉ tìm được tập đặc trưng con cận tối ưu
D) Chỉ tìm được tập đặc trưng con tốt hơn tập đặc trưng gốc
Đáp án: D) Chỉ tìm được tập đặc trưng con tốt hơn tập đặc trưng gốc
123.Đâu là ưu điểm của thuật toán Random Forest
A) Random Forest không bị overfitting
B) Random Forest bị overfitting
C) Random Forest xử lý nhanh
D) Random Forest chỉ có thể áp dụng cho bài toán hồi quy
Đáp án: A) Random Forest không bị overfitting
124.Tìm kiếm đặc trưng theo chiến lược Heuristic có đặc điểm gì
A) Không tìm được tập đặc trưng con tối ưu
B) Luôn tìm được tập đặc trưng con tối ưu
C) Chỉ tìm được tập đặc trưng con cận tối ưu
D) Chỉ tìm được tập đặc trưng con tốt hơn tập đặc trưng gốc
Đáp án: A) Không tìm được tập đặc trưng con tối ưu
125.Tìm kiếm đặc trưng theo chiến lược Heuristic có đặc điểm gì
A) Không tìm được tập đặc trưng con tối ưu
B) Luôn tìm được tập đặc trưng con tối ưu
C) Chỉ tìm được tập đặc trưng con cận tối ưu
D) Chỉ tìm được tập đặc trưng con tốt hơn tập đặc trưng gốc
Đáp án: A) Không tìm được tập đặc trưng con tối ưu
126.Overfitting xảy ra do vấn đề nào dưới đây
A) Dữ liệu mất cân bằng
B) Nhiễu trong dữ liệu
C) Dữ liệu có độ biến đổi cao
D) Cả 3 vấn đề trên
Đáp án: D) Cả 3 vấn đề trên
127.Giả sử bạn đang làm việc với bài toán phân lớp nhị phân và có 3 model với mỗi model có độ chính xác là 70%. Nếu bạn kết hợp kết quả của 3 model theo phương pháp bỏ phiếu (voting method) thì độ chính xác thấp nhất bạn nhận được là bao nhiêu”
A) 0.7
B) Lớn hơn hoặc bằng 70%
C) Luôn lớn hơn 70%
D) Có thể dưới 70%
Đáp án: A) 0.7
128.Hàm kích hoạt nào được sử dụng cho lớp đầu ra của model
A) ReLU
B) Sigmoid
C) Tanh
D) Không có trong các phương án trên
Đáp án: B) Sigmoid
129.Mạng CNN có những thành phần cơ bản nào
A) Convolutional layers, Pooling layers
B) Convolutional layers, Batch Normalization, Dense (Fully connected) layers
C) Convolutional layers, Pooling layers, Dense (Fully connected) layers
D) Convolutional layers, Dense (Fully connected) layers
Đáp án: C) Convolutional layers, Pooling layers, Dense (Fully connected) layers
130.Chọn đúng hàm kích hoạt cho lớp cuối cùng và hàm mất mát thích hợp nhất cho bài toán hồi quy có đầu ra là giá trị vô hướng
A) sigmoid và binary_crossentropy
B) sigmoid và mse
C) sigmoid và categorical_crossentropy
D) None và mse
Đáp án: D) None và mse
131.Hình ảnh dưới đây là biểu diễn của hàm kích hoạt nào
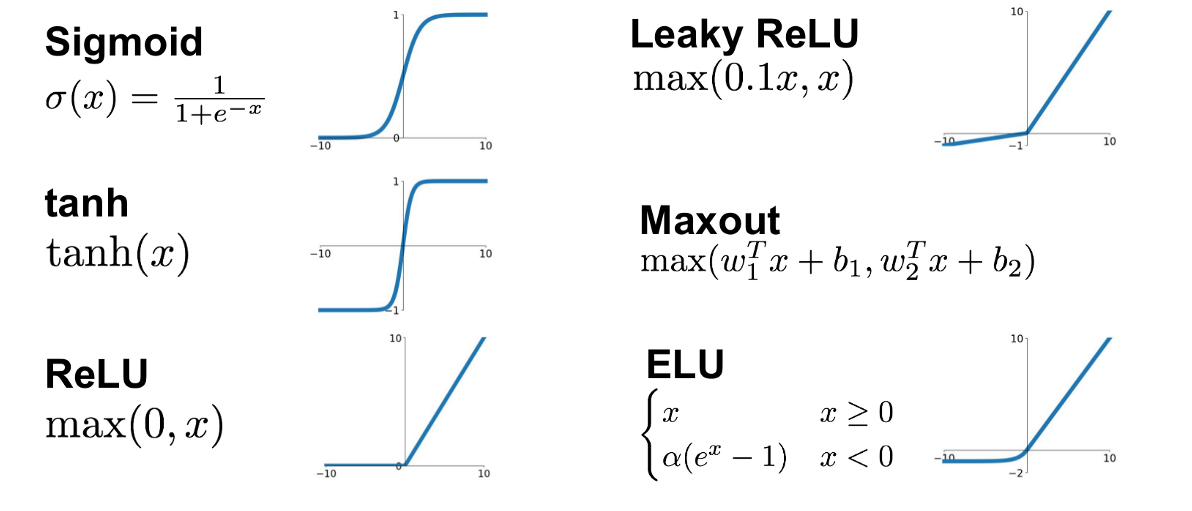
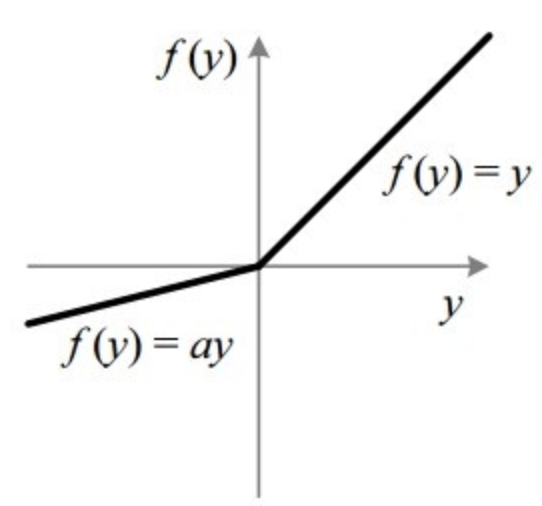
A) ReLU
B) LeakyReLU
C) SELU
D) ELU
Đáp án: B) LeakyReLU
132.Tham số nào không được gọi là Hyperparameter
A) Số nút của 1 lớp ẩn
B) Tốc độ học
C) Số epoch
D) Tất cả đều được gọi là Hyperparameter
Đáp án: A) Số nút của 1 lớp ẩn
133.Đoạn giả mã sau thể hiện nguyên lý hoạt động của mạng nào
t = 0
for input_t in N:
output_t = f(input_t, t)
t = output_t
A) Recurrent neural networks
B) Convolutional neural networks
C) Resnet
D) GoogleNet
Đáp án: A) Recurrent neural networks